|
ИИ приводит к важным исправлениям в компьютерном коде
|
|
|
|
Новые модели искусственного интеллекта (ИИ) для нагрева плазмы могут делать больше, чем считалось возможным ранее, не только увеличивая скорость прогнозирования в 10 миллионов раз при сохранении точности, но и корректно предсказывая нагрев плазмы в тех случаях, когда исходный цифровой код не сработал. Модели будут представлены 11 октября на 66-м ежегодном собрании отделения физики плазмы Американского физического общества в Атланте.
|
|
|
|
"Благодаря нашему интеллекту мы можем обучить искусственный интеллект выходить даже за рамки доступных численных моделей", - сказал Альваро Санчес-Вильяр, младший физик-исследователь Принстонской лаборатории физики плазмы (PPPL) Министерства энергетики США. Санчес-Вильяр - ведущий автор новой статьи в журнале Nuclear Fusion, посвященной этой работе. Это было частью проекта, который охватывал пять исследовательских институтов.
|
|
|
|
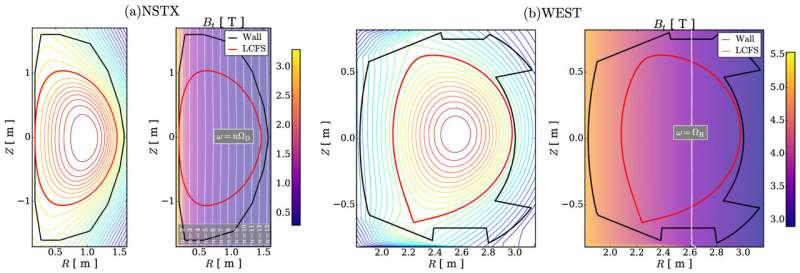
Модели используют машинное обучение, разновидность искусственного интеллекта, чтобы попытаться предсказать поведение электронов и ионов в плазме при нагреве в ионно-циклотронном диапазоне частот (ICRF) в экспериментах по термоядерному синтезу. Модели обучаются на основе данных, генерируемых компьютерным кодом. Хотя большая часть данных соответствовала предыдущим результатам, в некоторых экстремальных сценариях данные оказались не такими, как ожидалось.
|
|
|
|
|
|
|
"Мы наблюдали параметрический режим, при котором профили нагрева демонстрировали неустойчивые всплески в довольно произвольных местах", - сказал Санчес-Вильяр. "Не было ничего физического, что могло бы объяснить эти всплески".
|
|
|
|
Санчес Вильяр выявил и удалил проблемные данные, известные как выбросы, из тренировочного набора для обучения своего искусственного интеллекта, поскольку сценарии были нефизическими. "Мы скорректировали нашу модель, исключив всплески в обучающем наборе данных, и все равно смогли предсказать физику", - сказал Санчес Вильяр.
|
|
|
|
"Как можно заметить, код корректно удаляет всплески, но предполагает более высокий нагрев в выделенной области. Однако не было ничего, что гарантировало бы, что эти предсказания были физическими".
|
|
|
|
Затем команда пошла еще дальше. После нескольких месяцев исследований Санчес Вильяр выявил причину — ограничение числовой модели — и устранил ее, после чего запустил исправленную версию кода для более сложных случаев, в которых изначально наблюдались случайные всплески.
|
|
|
|
Он не только обнаружил, что решения не содержали всплесков во всех проблемных случаях, но, к его удивлению, эти решения были почти идентичны решениям в одной из моделей машинного обучения, предсказанных месяцами ранее, даже в критических сценариях с выбросами.
|
|
|
|
"Это означает, что на практике наша суррогатная реализация была эквивалентна исправлению исходного кода, просто на основе тщательного анализа данных", - сказал Санчес-Вильяр. "Как и в случае с любой технологией, при разумном использовании ИИ может помочь нам решать проблемы не только быстрее, но и лучше, чем раньше, и преодолевать наши собственные человеческие ограничения".
|
|
|
|
Как и ожидалось, модели также позволили сократить время вычислений для ICRF-нагрева. Это время сократилось примерно с 60 секунд до 2 микросекунд, что позволило ускорить моделирование без существенного снижения точности. Это улучшение поможет ученым и инженерам изучить наилучшие способы использования термоядерного синтеза в качестве практичного источника энергии.
|
|
|
|
Источник
|