|
Роботы теперь так же умны, как и люди
|
|
|
|
Чат-боты с искусственным интеллектом (ИИ), такие как ChatGPT, были разработаны таким образом, чтобы максимально точно воспроизводить человеческую речь для улучшения взаимодействия с пользователем. Но по мере того, как искусственный интеллект становится все более совершенным, становится все труднее отличать эти компьютерные модели от реальных людей.
|
|
|
|
Ученые из Калифорнийского университета в Сан-Диего (UCSD) сообщают, что два ведущих чат-бота достигли важного рубежа.
|
|
|
|
Как GPT, который поддерживает функцию ChatGPT в OpenAI, так и LLaMa, которая стоит за Meta AI в WhatsApp и Facebook, прошли знаменитый тест Тьюринга.
|
|
|
|
Разработанный британским взломщиком кодов времен Второй мировой войны Аланом Тьюрингом в 1950 году, тест Тьюринга, или "имитационная игра", является стандартной мерой для проверки интеллекта машины.
|
|
|
|
Искусственный интеллект проходит тест, когда человек не может правильно определить разницу между ответом другого человека и ответом ИИ.
|
|
|
|
|
|
|
"Полученные результаты являются первым эмпирическим доказательством того, что любая искусственная система проходит стандартный трехсторонний тест Тьюринга", - говорят ученые UCSD.
|
|
|
|
"Если следователи не в состоянии надежно отличить человека от машины, то считается, что машина прошла проверку".
|
|
|
|
Исследователи использовали четыре модели искусственного интеллекта – GPT-4.5 (выпущенную в феврале), предыдущую версию под названием GPT-4o, флагманскую модель Meta LLaMa и чат-программу 1960-х годов ELIZA.
|
|
|
|
Первые три – это "большие языковые модели" (LLM) - алгоритмы глубокого обучения, которые могут распознавать и генерировать текст на основе знаний, полученных из массивных наборов данных.
|
|
|
|
Эксперты набрали 126 студентов-старшекурсников из Калифорнийского университета в Сан-Диего и 158 человек из онлайн-пула данных Prolific.
|
|
|
|
Участники вели пятиминутные онлайн-беседы одновременно с другим участником–человеком и одним из ИИ, но они не знали, кто есть кто, и им приходилось решать, кого из них они считают человеком.
|
|
|
|
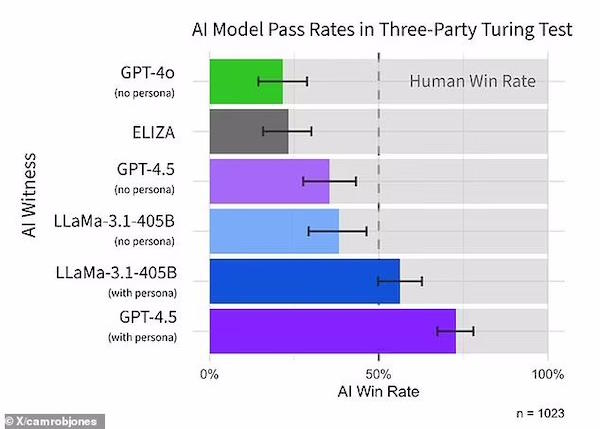
Когда ему было предложено принять человеческий облик, GPT-4.5 был признан человеком в 73 процентах случаев – чаще, чем выбирался реальный участник-человек.
|
|
|
|
Такой высокий процент говорит о том, что у людей было больше шансов определить, является ли GPT-4.5 человеком или машиной.
|
|
|
|
Между тем, лама-3.1 из Meta, когда ей также предложили принять человеческий облик, была признана человеком в 56 процентах случаев.
|
|
|
|
Команда отмечает, что это было "ненамного чаще или не реже, чем у людей, с которыми их сравнивали", но все равно считается достижением.
|
|
|
|
Наконец, в базовых моделях (ELIZA и GPT-4o) процент выигрышей был значительно ниже случайного – 23% и 21% соответственно.
|
|
|
|
Исследователи также попытались дать моделям более простые подсказки, не прибегая к подробным инструкциям, в которых им предлагалось принять человеческий облик.
|
|
|
|
Как и ожидалось, модели с искусственным интеллектом в этих условиях работали значительно хуже, что подчеркивает важность того, чтобы чат–боты в первую очередь запрашивали подсказки.
|
|
|
|
Команда утверждает, что их новое исследование, опубликованное в виде предварительной печати, является "убедительным доказательством" того, что боты OpenAI и Meta прошли тест Тьюринга.
|
|
|
|
"Это следует рассматривать как одно из многих других доказательств того, что LLMs демонстрирует высокий уровень интеллекта", - сказал ведущий автор Кэмерон Джонс в статье X thread.
|
|
|
|
Джонс признал, что ИИ показали лучшие результаты, когда их заранее проинструктировали о том, как выдавать себя за человека, но это не значит, что GPT–4.5 и LLaMa не прошли тест Тьюринга.
|
|
|
|
"Действительно ли ИИ прошли, если им нужна была подсказка? Это хороший вопрос", - сказал он в теме "Х".
|
|
|
|
"Без каких-либо подсказок LLMS потерпели бы неудачу по тривиальным причинам (например, признались в том, что они являются искусственным интеллектом), и их можно было бы легко настроить так, чтобы они вели себя так, как они ведут себя при появлении запроса, поэтому я думаю, будет справедливо сказать, что LLMS проходят".
|
|
|
|
В прошлом году другое исследование, проведенное командой, показало, что две предшествующие модели OpenAI – ChatGPT-3.5 и ChatGPT-4 – обманывали участников в 50% и 54% случаев (в том числе, когда им предлагалось принять человеческий облик).
|
|
|
|
Поскольку GPT-4.5 уже набрал 73%, это говорит о том, что модели ChatGPT все лучше и лучше имитируют людей.
|
|
|
|
Это происходит спустя 75 лет после того, как Алан Тьюринг представил окончательный тест компьютерного интеллекта в своей основополагающей работе "Вычислительные машины и интеллект".
|
|
|
|
Тьюринг представил себе, что участник-человек будет сидеть у экрана и разговаривать либо с человеком, либо с компьютером через текстовый интерфейс.
|
|
|
|
По мнению Тьюринга, если бы компьютер нельзя было отличить от человека по широкому спектру возможных признаков, нам пришлось бы признать, что он так же разумен, как и человек.
|
|
|
|
С версией эксперимента, в которой вас просят определить разницу между человеком и искусственным интеллектом, можно ознакомиться на сайте turingtest.live.
|
|
|
|
Тем временем предварительная версия статьи опубликована на онлайн-сервере arXiv и в настоящее время проходит экспертную оценку.
|
|
|
|
Источник
|