|
Рассуждающий ИИ скоро замедлится в развитии
|
|
|
|
Логическим моделям, таким как OpenAI o3, меньше года, но их возможности уже значительно улучшились, и исследователи OpenAI с оптимизмом смотрят на то, что этот прогресс будет продолжаться.1 Но пока неясно, насколько масштабируемыми могут быть методы, используемые для обучения моделей мышления. Изучив этот вопрос, я думаю, что есть возможности для дальнейшего расширения обучения мышлению, но маловероятно, что OpenAI или другие разработчики frontier AI смогут масштабироваться на много порядков.
|
|
|
|
Если обучение логическому мышлению будет увеличиваться в 10 раз каждые несколько месяцев, в соответствии со скачком с o1 на o3, то вскоре, возможно, в течение года, оно достигнет предела общих вычислений для обучения. На этом этапе скорость масштабирования замедлится и сравняется с общим темпом роста числа обучающих компьютеров, составляющим ~4 раза в год. После этого прогресс в моделях логического мышления также может замедлиться.
|
|
|
|
Какой объем вычислений используется для обучения основному мышлению?
|
|
|
|
o3 и другие модели логического мышления OpenAI были разработаны на основе традиционных LLM, которые прошли обучение на огромном объеме человеческих данных в процессе, называемом “предварительной подготовкой”. Затем они проходят этап обучения с подкреплением, на котором получают отзывы о своих решениях сложных задач, что улучшает их логические способности.2 Этот второй этап я называю “тренировкой рассуждения”.
|
|
|
|
|
|
|
Исторически масштабирование обучающих вычислений было очень важной составляющей прогресса ИИ. Поэтому стоит проанализировать, какой объем вычислений в настоящее время используется, в частности, для обучения логическому мышлению, насколько это может быть масштабируемо и что это означает для улучшения этих моделей.
|
|
|
|
К сожалению, общедоступная информация о количестве вычислений, необходимых для обучения логическому мышлению для моделей логического мышления, скудна, несмотря на их широкое распространение в индустрии искусственного интеллекта. Вот что мы знаем:
|
|
|
|
- В OpenAI заявили, что o3 в 10 раз превосходит o1 в обучающих вычислениях, что почти наверняка относится к reasoning training compute. o3 был выпущен всего через четыре месяца после o1.
|
|
- Мы не знаем, какие вычислительные средства для обучения reasoning используются в o1, но мы оценили эффективность обучающих вычислений DeepSeek-R1, которая, возможно, является сопоставимой моделью.
|
|
- У нас также есть информация о нескольких других моделях reasoning, таких как Phi-4-reasoning от Microsoft и Llama-Nemotron от Nvidia.
|
|
- У нас есть потенциально информативное заявление от Дарио Амодея из Anthropic.
|
|
|
|
Я рассмотрю каждое из них по очереди.
|
|
Масштабирование от o1 до o3
|
|
|
|
OpenAI опубликовал этот график, показывающий производительность o3 и o1 в тесте AIME, сопоставленный с наиболее вероятным объемом вычислений, используемых при обучении reasoning. Он показывает, что окончательная версия o3 была обучена в 10 раз большему объему вычислений, чем o1.
|
|
|
|
Ось x, скорее всего, показывает вычисления для обучения рассуждениям, а не общие вычисления, потому что первая версия o1, в которой вычислений на четыре порядка меньше, чем в o3, набирает около 25% в AIME, и это было бы маловероятно, если бы ось x означала общие вычисления.3 Эта диаграмма также не имела бы особого смысла, если бы ось x была общей для вычислений, поскольку это означало бы, что OpenAI обучил множество версий o1 с крайне неполными этапами предварительной подготовки.
|
|
|
|
Если o3 был обучен в 10 раз большему количеству логических вычислений, чем o1, что это говорит о его абсолютном масштабе вычислений? У нас нет точной информации, но мы можем поискать подсказки в других моделях логических вычислений и заявлениях инсайдеров индустрии искусственного интеллекта.
|
|
Выводы из DeepSeek-R1
|
|
|
|
Большинство передовых разработчиков ИИ относительно мало рассказывают о том, как они обучают модели мышления. Главным исключением здесь является DeepSeek и его модель мышления R1.
|
|
|
|
В предыдущем выпуске этого информационного бюллетеня Эге Эрдил подсчитал, что DeepSeek-R1 был обучен на флопе ~ 6e23 (стоимостью ~ 1 миллион долларов) во время обучения RL reasoning, что потребовало генерации около 2 триллионов токенов. Это составляет около 20% от стоимости предварительной подготовки базовой модели DeepSeek-R1, DeepSeek-V3.
|
|
|
|
Хотя в этой оценке много неопределенностей, она полезна, потому что DeepSeek-R1 - это логическая модель с очень похожими контрольными показателями, что и o1. Поэтому было бы разумно использовать ее для определения базовой линии для наших оценок вычислений o1.
|
|
|
|
Однако шкала логических вычислений DeepSeek-R1 может отличаться от шкалы o1 по разным причинам. Вероятно, их количество соответствующих параметров отличается (хотя мы не знаем, насколько).4 И мы не знаем, как сравниваются этапы обучения логическим вычислениям с точки зрения эффективности вычислений.5
|
|
Выводы из других логических моделей
|
|
|
|
Две другие логические модели с подробной информацией об обучении - это Llama-Nemotron Ultra 253B от Nvidia и Phi-4-reasoning от Microsoft.
|
|
|
|
- Этап разработки RL на Llama-Nemotron Ultra занял 140 000 часов, или около 1 часа 23 минуты, что составляет менее 1% от стоимости предварительной подготовки исходной базовой модели.6
|
|
- У Phi-4-reasoning был гораздо меньший этап анализа, он генерировал около ~ 460 миллионов токенов, что стоило менее 1e20 флопа, или <0,01% вычислительных затрат на предварительное обучение.7
|
|
|
|
Оба устройства имеют впечатляющие показатели, а Llama-Nemotron сравним с DeepSeek-R1 и o1.
|
|
|
|
Однако эти оценки могут быть неинформативны в отношении моделей рассуждения, которые продвинулись вперед, таких как o1 или o3, из-за синтетических данных. Этапам RL для Llama-Nemotron и Phi-4-reasoning предшествовала контролируемая доводка, в ходе которой участники обучались на примерах высококачественных логических цепочек, и большая часть этих данных была получена на основе синтетических данных из других моделей рассуждения.8
|
|
К какому выводу мы можем прийти?
|
|
|
|
В целом, неясно, проливают ли они много света на обучающие вычисления o1 или o3.
|
|
|
|
Один из выводов заключается в том, что вычислительные затраты на обучение рассуждениям, по крайней мере на этапе обучения с подкреплением, могут быть относительно низкими для некоторых моделей, таких как Phi-4. Это не означает, что o3 был обучен на столь же малом объеме вычислений, но это означает, что трудно судить о масштабе вычислений reasoning только по тому факту, что модель reasoning хорошо работает в тестовом режиме.
|
|
|
|
Кроме того, при разработке логических моделей важную роль может сыграть старомодная контролируемая тонкая настройка, и из-за такого разнообразия подходов трудно оценить масштаб обучения логическим рассуждениям для моделей, не раскрывая подробностей обучения. Это также делает неясным, что следует считать “вычислением логических рассуждений” или “обучением логическим рассуждениям”. Обучение с подкреплением, вероятно, является основной движущей силой улучшений на стыке моделей мышления и поэтому должно быть в центре внимания, но я не слишком уверен в этом.
|
|
|
|
Последний намек на вычислительный масштаб существующих моделей рассуждения содержится в эссе, написанном генеральным директором Anthropic Дарио Амодеем в январе 2025 года, после выхода o1 и DeepSeek-R1 и анонса o3 (выделено мной).:
|
|
|
|
- Важно отметить, что, поскольку этот тип RL является новым, мы все еще находимся на ранней стадии масштабирования: сумма, затрачиваемая на второй этап RL, невелика для всех игроков. Потратив $ 1 млн вместо $ 0,1 млн, можно получить огромную прибыль. В настоящее время компании очень быстро работают над расширением второго этапа до сотен миллионов и миллиардов человек, но важно понимать, что мы находимся в уникальной “точке пересечения”, где существует мощная новая парадигма, которая находится на ранней стадии масштабирования и, следовательно, может быстро принести большие выгоды.
|
|
|
|
Я не уверен, отражают ли оценки Amodei в размере 0,1 млн долларов или 1 млн долларов стоимость обучения для какой-либо конкретной модели, такой как o1, o3 или DeepSeek-R1, или это просто общие гипотезы. И убеждения Амодея относительно вычислительного масштаба неантропных моделей, по-видимому, являются всего лишь предположениями, основанными на собственных данных Антропика. Но очевидно, что он считает, что стоимость обучения логически обоснованных моделей на сегодняшний день значительно ниже “сотен миллионов”, что было бы >1э26 ПРОВАЛОМ.9
|
|
|
|
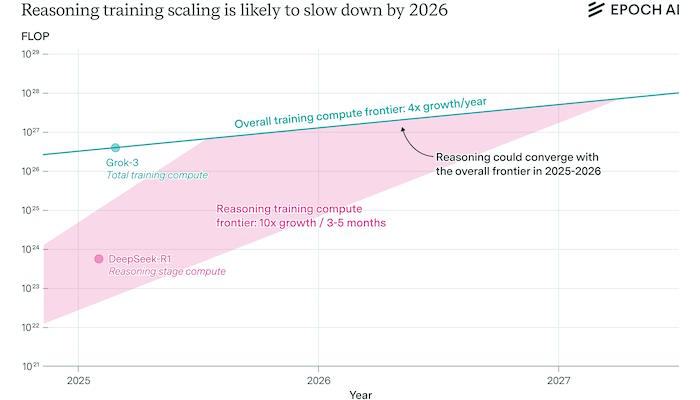
В целом, эти оценки и намеки свидетельствуют о том, что шкала логических вычислений o1 и, скорее всего, также o3 все еще ниже шкалы крупнейших тренировочных прогонов на сегодняшний день.
|
|
|
|
Однако они, вероятно, не на много порядков отстают от общего уровня вычислений, который составляет >1э26 сбоев, потому что у нас есть два примера моделей, обученных на более чем 1э23 сбоях на этапе анализа (DeepSeek-R1 и Llama-Nemotron Ultra). o1 и особенно o3 можно было бы обучить еще большему количеству людей.
|
|
Что означает масштаб вычислений с помощью рассуждения для прогресса ИИ?
|
|
|
|
Существующий масштаб вычислений в моделях логического мышления имеет важное значение для прогресса ИИ в ближайшей перспективе. Если уровень обучения логическому мышлению все еще относительно низок, мы можем увидеть быстрое увеличение масштабирования в краткосрочной перспективе, а также реальных возможностей.
|
|
|
|
Мы знаем, что o3 в 10 раз превосходит o1 по масштабируемости вычислений и обладает значительно большими возможностями, чем o1. Это включает в себя улучшение результатов в стандартных тестах по математике, естественным наукам и программированию. o3 также намного превосходит o1 в наборе программного обеспечения METR для агентурного обеспечения и задач кодирования.
|
|
|
|
Хотя я не знаю о каких-либо тщательных исследованиях законов масштабирования для обучения рассуждениям, как это делается для законов масштабирования перед обучением, OpenAI показал кривые масштабирования, которые выглядят довольно похожими на классические законы логарифмического линейного масштабирования (см. рис. 3 ниже и рис. 2 выше). На втором рисунке в статье DeepSeek-R1 также показано, что точность увеличивается по мере прохождения этапов обучения логическому мышлению примерно логарифмически линейным образом. Это говорит о том, что эффективность обучения логическому мышлению повышается аналогично предварительной подготовке, по крайней мере, для задач по математике и программированию. Таким образом, в течение следующих нескольких лет мы могли бы увидеть как значительные, так и быстрые улучшения.
|
|
|
|
Если reasoning compute достигнет масштабов total training compute, темпы его роста сравняются с общими темпами роста, которые в настоящее время составляют около 4 раз в год, а не 10 раз каждые несколько месяцев (как при переходе от o1 к o3).
|
|
|
|
Таким образом, если уровень подготовки по логическому мышлению всего на несколько (скажем, менее чем на три) порядков ниже общего уровня, этот темп роста может замедлиться в течение года или около того.10
|
|
Может ли логическое мышление на самом деле масштабироваться?
|
|
|
|
Конечно, рассуждать о масштабировании не так просто, как о выделении большего количества графических процессоров. Масштабирование может приостановиться из-за нехватки данных. Обучение логическому мышлению включает в себя обучающие модели для решения сложных задач, но существует не неограниченный набор подходящих задач, и может быть трудно найти, написать или искусственно сгенерировать достаточно разнообразных задач для дальнейшего масштабирования.
|
|
|
|
Также крайне неясно, насколько хорошо обучение логическому мышлению распространяется на более сложные области, не связанные с математикой и программированием.11 Кроме того, могут возникнуть другие непредвиденные проблемы.
|
|
|
|
Связанная с этим проблема заключается в том, что общие вычислительные затраты на разработку логических моделей могут быть намного больше, чем прямые затраты на основное обучение. Это может произойти, если лабораториям искусственного интеллекта придется проводить множество параллельных экспериментов, чтобы увидеть, какие проблемы, модели вознаграждения и другие методы действительно работают.
|
|
|
|
До сих пор я пытался оценить прямые затраты на обучение логическому мышлению в этом посте, но мы на самом деле не знаем, как OpenAI оценивает вычислительную мощность обучения для моделей логического мышления. И у нас нет никакой информации о затратах на исследования, даже от относительно прозрачных разработчиков.
|
|
|
|
Эти затраты, вероятно, будут несколько снижаться по мере развития логической парадигмы. И стоимость исследований не отменяет взаимосвязи между масштабом прямых вычислений и возможностями. Но если для проведения исследований требуются постоянные накладные расходы, то логические модели могут масштабироваться не так широко, как ожидалось.
|
|
|
|
С другой стороны, логические модели могут продолжать быстро совершенствоваться даже после замедления роста вычислительной мощности. Возможно, на сегодняшний день большая часть прогресса в логических моделях на самом деле вызвана инновациями в данных или алгоритмах. Но быстрое масштабирование вычислений потенциально является очень важным компонентом для разработки логической модели, поэтому за этим стоит внимательно следить.
|
|
|
|
Как бы то ни было, исследователи из OpenAI (вместе с Дарио Амодеем, как отмечалось выше) в настоящее время выражают уверенность в том, что они смогут быстро расширить модели мышления и добиться дальнейших улучшений. Поскольку эти инсайдеры непосредственно осведомлены о следующей итерации логических моделей, я думаю, что весьма вероятно, что o3 не достигла предела ни по масштабам, ни по возможностям.
|
|
|
|
Источник
|